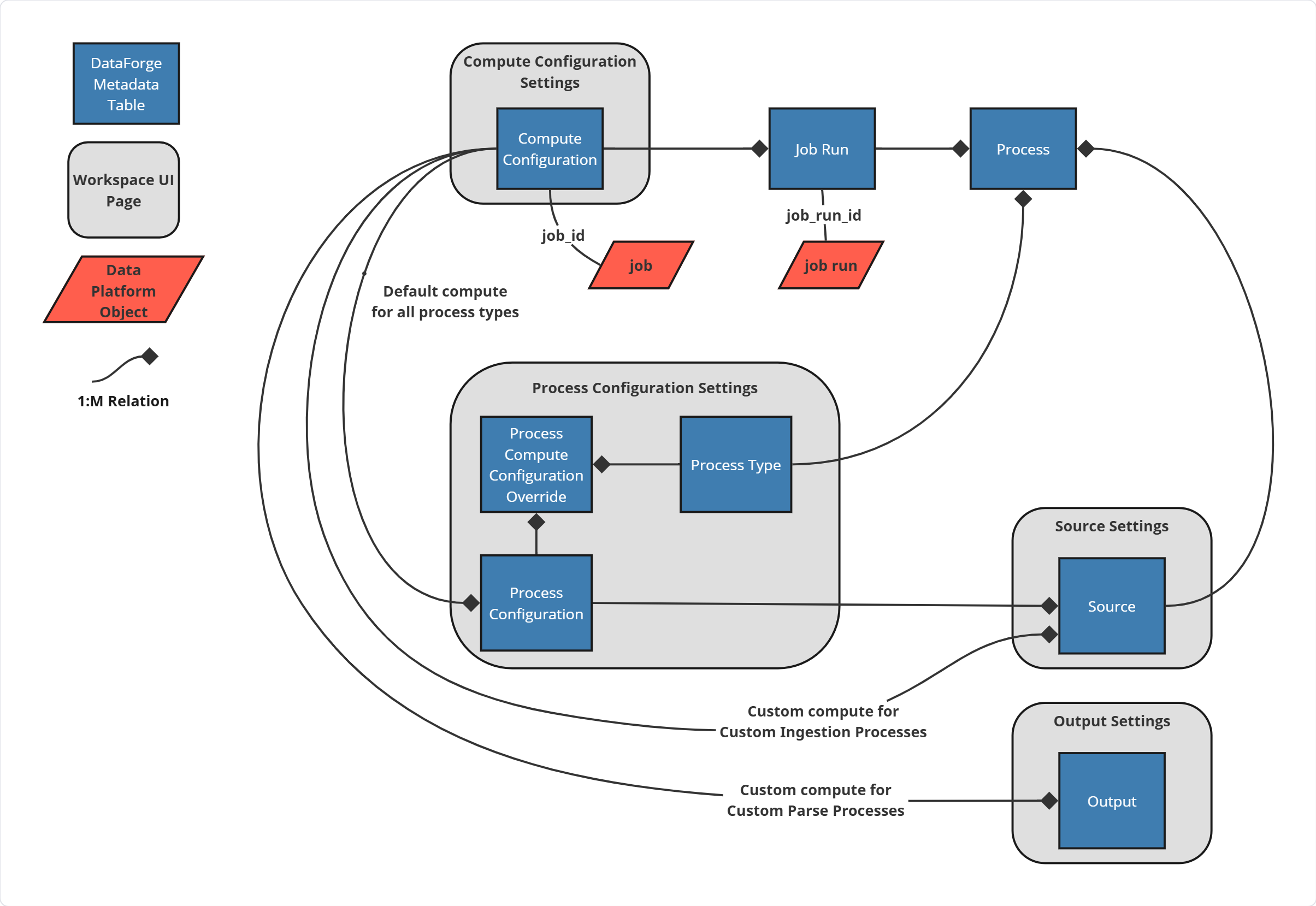
Compute and Process Configuration Overview¶
Terms and definitions¶
| Object | Description |
|---|---|
| Compute Configuration | Stores all configuration settings required for the databricks job: compute configuration, job configuration + few DataForge-specific parameters used to control job execution. Compute configuration record is directly linked to the databricks job via unique job_id attribute. |
| Process Configuration | Comprised of one default compute configuration and optional set of compute configurations for each specific process type. Process configuration is attached to each Source in DataForge. |
Below is high level diagram representing relationship of compute and process configurations to other DataForge metadata tables and Databricks objects