Spark and Databricks Overview¶
To minimize costs and processing times, you can override default cluster sizing and storage partitioning to tune the most computationally expensive processes. This guide covers the Spark and Databricks concepts needed for performance tuning within DataForge. For DataForge Cluster Configs and Processes, see the Cluster and Process Configuration Overview.
Spark Structures/Services Overview¶
Effective tuning requires understanding how Spark breaks complex processes into parallelizable units of work and distributes them across cluster resources.
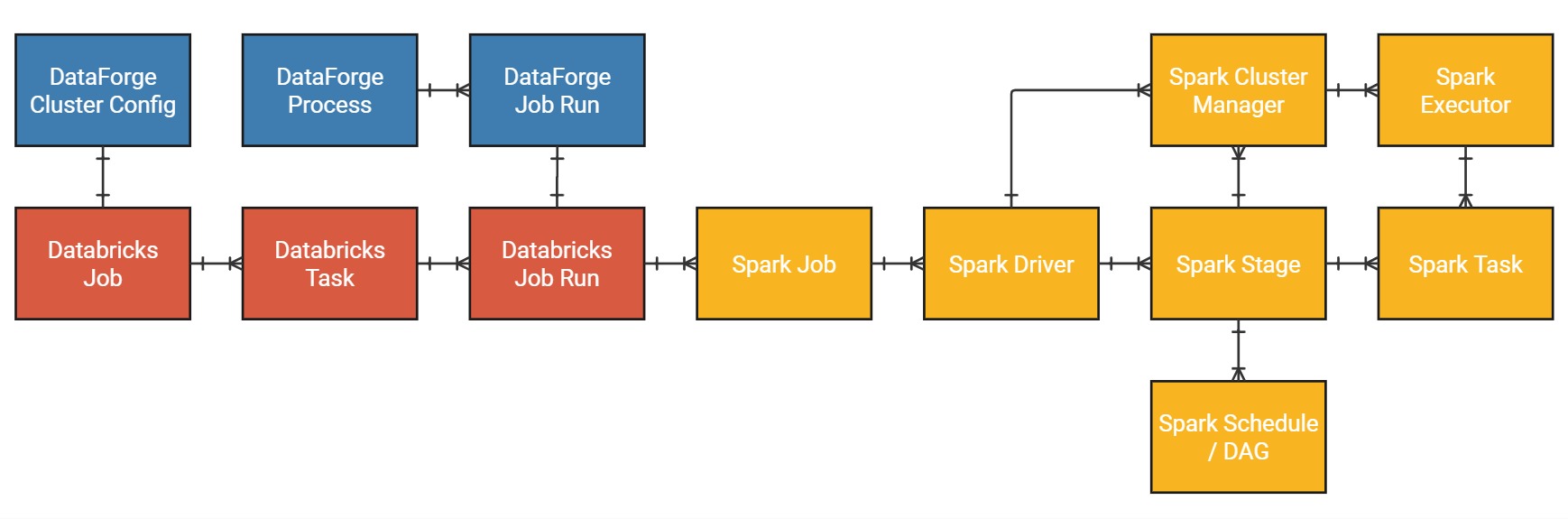
Databricks Job¶
A Databricks Job is a set of configurations to run non-interactive code within Databricks. It includes what tasks to run (notebook, pipeline, asset bundle, JAR, etc.), what type of cluster to run the code on, and optionally, what order to run Databricks Tasks in.
DataForge Cluster Configuration¶
A DataForge Cluster Configuration is a wrapper around a Databricks Job that allows users to integrate Databricks Job configurations with the rest of the DataForge Meta structures, as well as use Databricks Jobs in unique ways not natively supported by Databricks.
Databricks Task¶
A Databricks Task is a logical grouping of non-interactive code. All DataForge-managed jobs (including Custom Notebooks via SDK) have one task per job; DataForge does not support multi-task Databricks pipelines or custom orchestration.
DataForge Process¶
While Databricks Tasks are roughly analogous to DataForge Processes, they lack the features needed for DataForge's framework and workflow engine — so DataForge Processes are a completely separate entity with no relation to Databricks Tasks.
Databricks Job Run¶
A Databricks Job Run is a specific execution (not to be confused with a Spark Executor) of a defined Databricks Task. This is the logical representation of the instance of spun-up infrastructure (cluster) created based on the settings of the Databricks Job.
DataForge Job Run¶
An DataForge Job Run is a wrapper around a Databricks Job Run for purposes of integration with the DataForge meta structures via the DataForge Process structure. Processes can run both concurrently and sequentially on a single Job Run - managed automatically by DataForge's resource management engine and configurable via DataForge Cluster Configuration and an object not covered in this article: Process Configuration.
Spark Driver¶
The Spark Driver translates your code into Spark Jobs, Spark Stages, Spark Tasks, and Directed Acyclic Graphs (DAGs). Once these structures are generated, the Driver requests Spark Executors from the Cluster Manager to begin processing.
Spark Job¶
A Spark Job is a stand-alone execution of parallelizable code, bounded by a Spark Action. Each action produces a separate job executed lazily in FIFO order. No data is shared between jobs by default; developers must manually code persistence hand-offs between action sub-segments — see the Spark persistence docs and this Databricks overview PDF.
Spark Stage¶
A Spark Stage is an execution plan for a portion of a Spark Job, delineated by computational boundaries such as type of transformation, narrow vs. wide.
Cluster Manager¶
The Cluster Manager acts as the interface between the Driver and Executors. It allocates resources to Driver(s) and distributes Tasks to workers. It also is responsible for tracking the success, failure, and retries of individual tasks, as well as the overall Spark Job status.
Spark Executor¶
A Spark Executor is an abstraction of a combination of compute and memory resources.
Spark Task¶
A Spark Task represents an atomic unit of work to be acted upon.