How it Works¶
Alloy Refinement Process¶
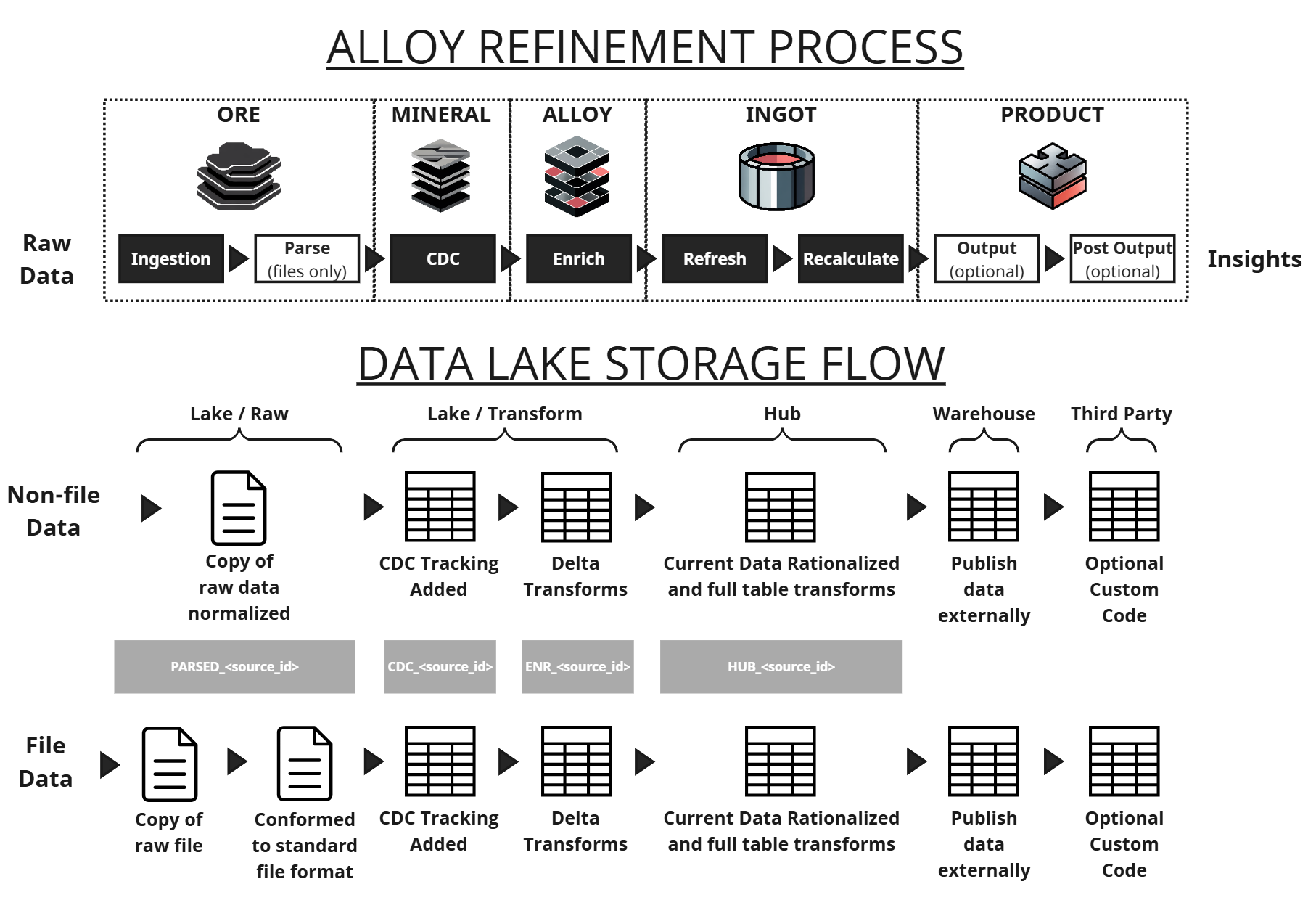
Alloy refinement process and corresponding storage locations
As seen in the above data flow diagram, DataForge intakes raw data, runs it through the Alloy refinement process and outputs an organized data warehouse. The refinement process consists of Ore, Mineral, Alloy, Ingot, and Product. Each of these stages of Alloy refinement are stored in tables, allowing you to easily query and inspect intermediate results directly. Alloy refining can be equated to 5 mandatory steps and 3 optional steps: Ingestion, Parse (for files only), Capture Data Changes (CDC), Enrichment, Refresh, Recalculation, Output (optional), and Post-Output (optional).
The data storage flow consists of four main structures: Raw Data, Data Lake, Data Hub, and Data Warehouse. Though not shown in the diagram, each step in each flow consists of generated and configuration metadata to aid the user in process management and configurations respectively.
To illustrate how the DataForge refinement process works, we will dive into each step and it's components.
Ore¶
Unrefined data captured exactly as delivered from the source.
DataForge does not generate or store data. DataForge relies on external raw data sources, and supports many types of data sources such as files, databases, APIs, and events.
Ingestion is the first step in the refinement process where data is copied from external data sources and ingested into the DataForge framework, ultimately creating a new table in Databricks or Snowflake. As DataForge ingests data for the refinement process, it identifies and stores information such as source database, original file location, and source schema within Ember, resulting in a self-managing data lake.
As file data can vary in format and nature, the Parse step is run after Ingestion for files to standardize/normalize the format of all data (think nomenclature and data types) before further refinement.
Both of these steps are facilitated by the Connections and Sources that you define.
Mineral¶
Purpose-built change detection isolates only the new or updated records.
The Mineral stage of the refinement process consists of DataForge detecting new or changed records within the data that has been ingested compared to data that is already refined. This Capture Data Changes process is driven based on the settings you optionally change within your Source, such as the refresh type.
Alloy¶
Business logic, joins, and enrichment are applied only to the incremental batch - improving both performance and predictability.
With a clean, well-formatted table listing all the records that need updating, it is time to enrich your data with Alloy through data quality checks and additional business logic. User-specified rules are created and managed for each dataset through the Source Relations and Rules interfaces to drive transformations and processing during an Enrichment step. DataForge provides a flexible, yet guided framework for data management, to assist you in creating always-valid relations between sources which allow you to transform your data using any combination of references across your datasets without concern for data duplication and bad joining of data.
The Alloy process runs all of your business logic and rule transformations, appending new columns to the existing table containing only the records that need updating.
Ingot¶
The enriched batch is merged into the full dataset through a consistent refinement process that ensures clean, canonical results.
Each source has a hub table representing the truth of the most up-to-date data. The Ingot process begins with a Refresh step, which merges the results of Alloy into the hub table. As data moves through processing steps, DataForge automatically and continuously modifies the underlying table structures to ensure optimal performance.
After Refresh, the Recalculate step runs which recalculates rules that you've identified to always keep current for historical data that has already run through the refinement process.
The result of the Ingot process is a finalized source hub table that is ready to be published or analyzed.
Product¶
Final data outputs are materialized for analytics, operational systems, and downstream consumers.
The Product process is a layer where you can optionally combine and publish your refined data to external locations for consumption downstream. After data is fully refined in your source hub table, the Output step runs to publish your data externally to one or more destinations you choose, such as different tables or materialized views, files, or events, etc.
The Product phase allows you to use the pre-existing relation logic to combine and stack transformed data sets across your Sources to a single location. This phase of the process typically consists of very limited transformation logic, instead focusing on mappings of data sets and data fields from the source hub tables to the final location(s).
The Output step is facilitated by the Connections and Outputs screens in the DataForge interface.
DataForge supports most column-oriented storage technologies, such as SQL Server, Snowflake, Parquet, etc. and can fully manage the table structures, data models, and maintenance operations. However, you can optionally define custom code using the DataForge SDK to achieve anything you need that is not already provided. Any custom code is run as a Post Output step after Output completes.
Ember Metadata¶
Ember, DataForge's structured data catalog and declarative metadata engine, is used to drive all data processing during refinement. Ember consists of a combination of user, system, and process driven metadata. It is the definition layer that tells Alloy exactly how each step of the refinement process should behave. Ember is a proprietary catalog that you can easily query in Databricks or Snowflake at any time to see any details of your configurations or monitor processing.